
Bu proje Avrupa Birliği tarafından finanse edilmiştir.
Örnek çalışmalar
Bu bölümde, yok olma tehlikesi altındaki diller ve azınlık dilleri için örnek veya ilham verici olduğunu düşündüğümüz dil teknolojisi ile ilgili bazı girişimleri ve çalışmaları listeliyoruz. Bu belgenin de bünyesinde hazırlandığı “Judeoespanyol: Akdeniz’in iki yakasını birleştiren dil” projesini anlatarak başlayıp Anadolu, İber, Afrika dillerini içeren projelerle devam edeceğiz.
Judeoespanyol: Akdeniz’in iki yakasını birleştiren dil
Col·lectivaT ve Sefarad Kültür Araştırma Merkezi (SKAD), sosyal medya için dil eğitimi içeriklerinin oluşturulmasından, Ladino’ya dijital çağa yardımcı olacak ileri dil teknolojilerinin geliştirilmesine kadar çok çeşitli faaliyetler gerçekleştirmek üzere bu proje için bir araya geldi. Ayrıca bu dilin Türkiye ile İspanya arasında ortak bir kültür mirası olduğu konusunda farkındalık oluşturmayı amaçlıyor.
Sosyal medya için görsel-işitsel içerik oluşturulması
Proje, sosyal medya platformlarında görünürlük kazanmaya yardımcı olacak ve genç nesilleri Ladino öğrenmeye çekecek kısa dil öğrenme videoları oluşturdu. Bu kısa videolarda bir Ladino cümleyi Türkçe, İngilizce ve İspanyolca çevirisi ile telaffuzunu öğrenmeye yardımcı olacak sesli bir şekilde sunuluyor.

Una Fraza al diya (Her gün bir cümle) videoları ile SKAD’ın Instagram sayfasında Ladino tanıtımı
Ladino Data Hub ve açık dil veri kümeleri
Proje, Ladino dil verilerini ve Sefarad kültürünün belgelenmesine yardımcı olan diğer kaynakları barındırmaya ayrılmış merkezi bir web arşivi görevi görecek olan Ladino Data Hub’ı oluşturdu. Dünyanın her yerinden araştırmacıların, gazetecilerin Ladino için araştırma ve geliştirmeyi arttırmaya yardımcı olacak veri kümelerine erişmesini ve bunları paylaşmasını sağlamayı amaçlıyor.
Ladino Data Hub, Ladino dili ve Sefarad kültürüyle ilgili verileri barındıyor
Proje, halihazırda var olan veri kümelerini yeniden paketledi, yeni veri kümeleri oluşturdu ve bu portalda paylaştı. Bunlar:
Şalom gazetesinden taranan cümlelerden oluşan bir metin derlemi
Una Fraza al diya cümlelerini ve ses kayıtlarını içeren sesli paralel metin derlemi
SKAD tarafından oluşturulan Ladino konuşma derlemi
Karen Şarhon tarafından okunan konuşma materyallerinden oluşan temiz konuşma sentezi eğitimi veri seti
Güler’in sözlüğüne dayanan İspanyolca Ladino sözlüğü (lexicon)
SKAD bünyesinde yapılan çevirilerden `Ladino, İngilizce ve Türkçe paralel metinler
Temel makine çevirisi modellerinin eğitimi için sentetik olarak üretilmiş paralel derlem
Makine çevirisi ve konuşma sentezi için web uygulaması
Projenin son ve en önemli çıktısı, Ladino ile Türkçe, İspanyolca ve İngilizce arasında çeviri yapabilen bir web uygulamasıdır. Amaç, Ladino öğrenmek isteyen kişilere, araştırmacılara ve dilbilimcilere yardımcı olmaktır. Makine çevirisi back-endi, kural tabanlı bir makine çeviri sistemi yardımıyla oluşturuldu. Bu, İspanyolca ve Ladino arasındaki benzer sözdiziminden faydalanıp, ancak sözlüklerden ve dilbilgisi kitaplarından türetilen bir dizi kuralla yazım ve kelime dağarcığını değiştirerek İspanyolca’dan LAdino’ya dönüştürebilen bir arkayüz. Web uygulaması ayrıca TTS eğitimi veri kümesi ile oluşturulmuş bir metin konuşma sentezi uygulaması ile Ladino cümleleri sentezleyebiliyor.
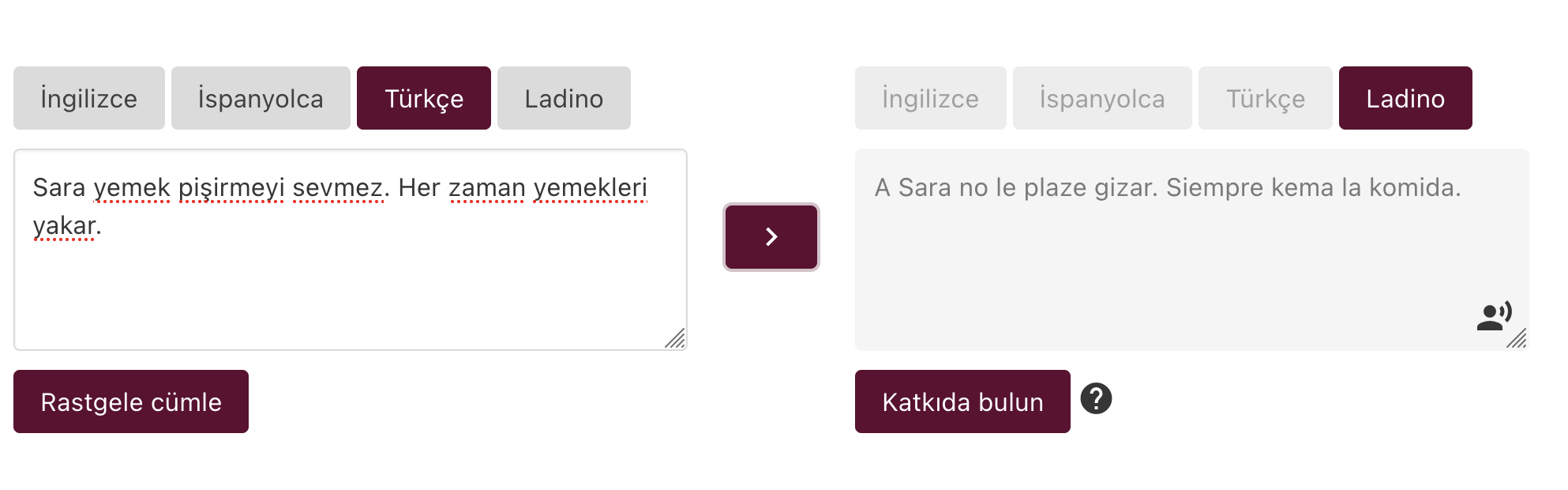
Konuşma sentezi ile Ladino çeviri web uygulaması
Web uygulaması ayrıca paralel verilere katkıda bulunmaya da izin verir. Kullanıcılar, Ladino için paralel verileri genişletmek için rastgele bir cümle yükleyebilir ve düzeltilmiş çevirilerini gönderebilir.
Not
Bu projenin ayrıntılı bir teknik raporu için Avrasya’daki Yerli, Tehlikedeki ve Az Kaynaklı Diller için Kaynaklar ve Teknolojiler Çalıştayında (EURALI) sunulan “Tehlike Altındaki Bir Dili Dijital Çağa Hazırlamak: Judeoespanyol Örneği” başlıklı makaleye bakabilirsiniz: Bağlantı yakında eklenecek
Tabandan örgütlenen NLP toplulukları
Dikkatlerini sadece birkaç dile veren NLP araştırmalarına karşı, tabandan gelen araştırma toplulukları, dünyadaki dilleri teknolojinin ön saflarına getirmek için bir araya geliyor. Bu girişimlere iki örnek Masakhane ve Turkic Interlingua.
Web sayfalarında tanımlandığı gibi, “Masakhane, misyonu Afrikalılar tarafından Afrikalılar için Afrika dillerinde NLP araştırmalarını güçlendirmek ve teşvik etmek olan bir taban örgütüdür.” Bu, adlarından da anlaşılacağı gibi “birlikte inşa etmek” için herkese açık bir girişimdir. Dil teknolojisi araştırmalarında Afrika’nın 2000 dilini temsil etmek amacıyla tüm dünyada Afrikalı ve Afrikalı olmayan araştırmacılar tarafından birçok eş zamanlı etkinlik gerçekleştirilmektedir. Masakhane’nin öne çıkan bazı çalışmaları:
Masakhane çeviri 6 Afrika dilini destekliyor: Yoruba, Shona, Lingala, Swahili, Tshiluba
Lanfrica Afrika dil eserlerini bulmada karşılaşılan zorluklara karşı koymak için Afrika dil kaynaklarını katalogluyor
BibleTTS Sahra Altı Afrika’da konuşulan on dil için yüksek kaliteli Metin Okuma modellerinin geliştirilmesini sağlıyor: Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, Chichewa, Akuapem Twi, Asante Twi, Yoruba.
MasakhaNER Know our names (MasakhaNER İsimlerimizi bilin), çeşitli Afrika dilleri için elle, adlandırılmış varlık tanıma (NER) veri kümeleri oluşturma
Masakhane ayrıca Afrika NLP ile ilgili araştırmaları yayınlamak için yıllık çalıştaylar düzenliyor ve Lacuna gibi veri toplama fonlarına katılıyor.
Turkic Interlingua (TIL), Altayca, Azerice, Başkurtça, Şorca, Kırım Tatarcası, Çuvaşça, Gagauzca, Karakalpakça, Hakasça, Kazakça, Karaçay-Balkarca, Kumukça, Kırgızca, Sahaca (Yakutça), Salarca, Türkmence, Türkçe, Tatarca, Tuvaca, Uygurca, Urumca ve Özbekçe gibi “Türkî diller için, misyonu yazım denetleyicilerinden çeviri modellerine kadar dil teknolojileri geliştirmek, çeşitli veri kümeleri toplamak ve dilbilimsel olguları akademik araştırma merceğinden incelemek olan bir araştırmacılar, mühendisler, dil meraklıları ve topluluk liderlerinden oluşan bir topluluktur.”
Common Voice kampanyaları
Çeşitli dil toplulukları, Common Voice’a katılımı harekete geçirmeye başladı. Bu girişimler, tek tek bireylerden yerel yönetimlere kadar uzanan gruplar tarafından oluşturuluyor. Bazı örnekler:
Igbo dili için Igwebuike topluluğu
Katalanca için AINA projesi
Common Voice’a yaptıkları katkılardan dolayı Katalan halkından özel olarak bahsetmek gerek. İspanya’da vatansız bir azınlıklaştırılmış dil olan Katalanca, aktivistlerin inanılmaz katkıları ve ayrıca Katalan yerel hükümetinin AI girişimi sayesinde Mayıs 2022 itibariyle Common Voice’taki 4.büyük dil.

New York Times Meydanı’nda “İnternetin Katalanca konuşmasının zamanı geldi” yazan bir reklam panosu (fotoğraf: Aina Martí)
Diğer girişimler
Bahsetmeye değer diğer bazı girişimler şunlar:
Col·lectivaT, Katalan kamu televizyon yayınlarını ve meclis oturumları kayıtlarını kullanarak Katalanca açık kaynak konuşma verileri ve metin derlemleri oluşturdu.
Catotron, Katalunya Kültür Bakanlığı’nın desteğiyle oluşturulmuş Katalanca ilk açık kaynak, sinir ağı (neural network) tabanlı konuşma sentezi motorudur.
Filipinler’in dilleri Cebuano ve Waray-Waray, makine çevirisinin rekabetçi kullanımı sayesinde en büyük Wikipedia sayfalarından birine sahiptir (kaynak)
Maori halkı, “kendi kaderini tayin hakkını korumak” için kendi dillerinde ses verileri toplamaya yönelik özel veya açık kaynaklı girişimleri reddetti (kaynak)
Hindistan Microsoft Research Tarafından ELLORA Düşük Kaynaklı Dilleri Etkinleştiriyor

Bu yayın Avrupa Birliğinin maddi desteği ile hazırlanmıştır. İçerik tamamıyla Col·lectivaT ve SKAD’ın sorumluluğundadır ve Avrupa Birliği’nin görüşlerini yansıtmak zorunda değildir.