
Bu proje Avrupa Birliği tarafından finanse edilmiştir.
Dil verileri
Yapay zeka (AI) araçları, tehlike altındaki diller ve azınlık dilleri için dil kaynağı oluşturma adına yeni bir alan açar. Sözlük, dil bilgisi belgeleri, dil haritaları vb. gibi dilleri korumak için oluşturulan “klasik” dil kaynaklarıyla karşılaştırıldığında, AI araçları daha az dilbilimsel uzmanlık gerektirir, ancak genellikle yalnızca büyük hacimlerde olduğunda yararlıdır.
Bu bölümde, bir önceki bölümde anlattığımız yapay zeka tabanlı dil teknolojilerinin oluşturulmasını besleyen veri türlerini açıklayacağız. Ayrıca, genellikle bu uygulamaların gerektirdiği gibi büyük hacimli olmasalar bile, bu verileri toplamanın ve bunlardan en iyi şekilde yararlanmanın bazı yollarını ele alacağız.
Metin derlemi
Dilbilimde, bir metin derlemi (İng. text corpus/corpora), bir dilde dijital formatta büyük ve yapılandırılmış bir metin kümesinden oluşan bir dil kaynağıdır. Derlem dilbiliminde (corpus linguistics) metin derlemlerinden, istatistiksel analiz yapmak ve hipotezi test etmek, oluşumları kontrol etmek veya belirli bir dil bölgesi içindeki dil kurallarını doğrulamak için faydalanılır. Dil teknolojileri açısından, optik karakter tanıma, el yazısı tanıma, makine çevirisi, yazım hataları düzeltme, bilgisayar destekli yazım gibi uygulamalarda kullanılan istatistiksel dil modellerinin oluşturulmasında önemli bir rol oynarlar.
Metin derlemleri kendi başlarına etiketlenmemiş veri türündedir. Yani, sadece bir veri yığınıdır (bu durumda metin), herhangi bir açıklama veya etiket içermez. Dil modelleri, dille ilgili bir “fikir edinmek” için kelime dizilerinin olasılıklarını depolar. Ayrıca, farklı NLP görevleri için etiketli veriler oluşturmak amacıyla metin derlemlerine aşağıdaki açıklamalar eklenebilir:
Sözcük türü (İsim, fiil, Sıfat vb.)
Adlandırılmış varlıklar (Kişi, konum, kişisel olarak tanımlanabilir bilgiler, kurum, zaman vb.)
Lemma (kelime kökleri, ör. kırdı için kırmak gibi)
Bağımlılık ve öbek yapısı (sözdizimi ağacı)
Metin derlemlerine kaynak sağlama
Metin derlemine kaynak sağlamanın en yaygın yolu, web’i taramaktır. Bu teknik, aynı anda belirli bir dilde veya birçok dilde metin toplamak için tüm web’i ayrıştırır (parse). Örneğin Wikipedia, içeriğini farklı dillerde yayınlar, bu da bir metin derlemi oluşturmak için kullanılabilir. Common Crawl inisiyatifi, web sitesi verilerini toplar ve halka petabaytlarca (1 PB=1024 terrabayt) veriyi ücretsiz olarak sağlar. OSCAR, bu verileri 166 dilde sınıflandırararak dağıtır.
Kaynağı olan diller için kullanılan bir diğer yaygın kaynak ise kitaplardır. BookCorpus web’den 74 Milyon cümle ve 984 Milyon kelime içeren 11.038 kitaptan oluşuyor ve büyük teknoloji şirketlerinin oluşturduğu birçok etki yaratan dil modelini desteklediği biliniyor.
Not
Web’de ve kitaplardaki dil/üslup önyargı ya da toksik dil içerir. Buralarda açıkta bulunan verilerden oluşturulan dil modelleri, gördüklerini temsil etmekten başka bir şey yapmaz. Dolayısıyla bu üsluplar, modellerde yeniden üretilir. Büyük dil derlemlerinden dil modelleri oluşturmanın olası risklerinin analizi için, Bender et al. tarafından yazılan bu makaleye bakabilirsiniz.
Paralel veri (bitext)
Paralel veri, bir makine çevirisi sistemi oluşturmak için ihtiyaç duyulan veri türüdür ve bir dildeki cümlelerin çevirileriyle birlikte bir araya gelmesinden oluşur. Tarihsel olarak paralel verilerin kaynağı Birleşmiş Milletler ya da Avrupa Parlamentosu gibi çok dilli kamusal alanlarda yapılan çeviriler olmuştur. Şu anda ise paralel metnin en büyük kaynağı çok dilli web’dir.
Makine çevirisi modellerini eğitmek için sadece tercüme edilmiş belgelere sahip olmak yeterli değildir. Metinlerin cümlelere bölünmesi ve hizalanması gerekir. Paralel metin hizalama, paralel metnin her iki tarafında birbirine karşılık gelen cümlelerin tanımlanmasıdır. Ortaya çıkan belgeler ya satır satır karşılık gelmeli ya da orijinal cümleleri ve çevirilerini aynı satırda içermelidir. Hunalign çevrilmiş belgelerden cümle hizalamaları oluşturmaya yardımcı olur. TMX uzantılı çeviri hafızası dosyaları (Translation Memories) da hali hazırda cümle cümle segmentlere ayrılmış olduğu için iyi paralel veriler oluşturur.
Paralel veriye kaynak sağlama
OPUS hemen hemen tüm kamuya açık paralel verilerin bir derlemesidir. Birçok araştırmacının, MT modelleri için kaynak verilerini toplamak veya paralel verilerini yayınlamak için başvurduğu ilk yerdir.
Paralel veriler için bazı yaygın kaynaklar şunlardır: Çok dilli web siteleri (ör. uluslararası haber kuruluşları), film altyazıları (bkz. OpenSubtitles), kutsal metinler, parlamento oturumları, yazılım yerelleştirme verileri.
Tatoeba.org ile kitle kaynaklı paralel veriler sağlama
Tatoeba, yabancı dil öğrenenlere yönelik hazırlanmış, çevirileri ile birlikte sunulan ücretsiz bir örnek cümleler veri tabanıdır. Açık ve ortak çalışma modeli aracılığıyla bir gönüllüler topluluğu tarafından yazılır ve sürdürülür. Bağışlarla finanse edilen kar amacı gütmeyen Fransız kuruluş Tatoeba Association tarafından sunulur. Şu anda 412 desteklenen dilde 10.397.308 cümle barındırır.
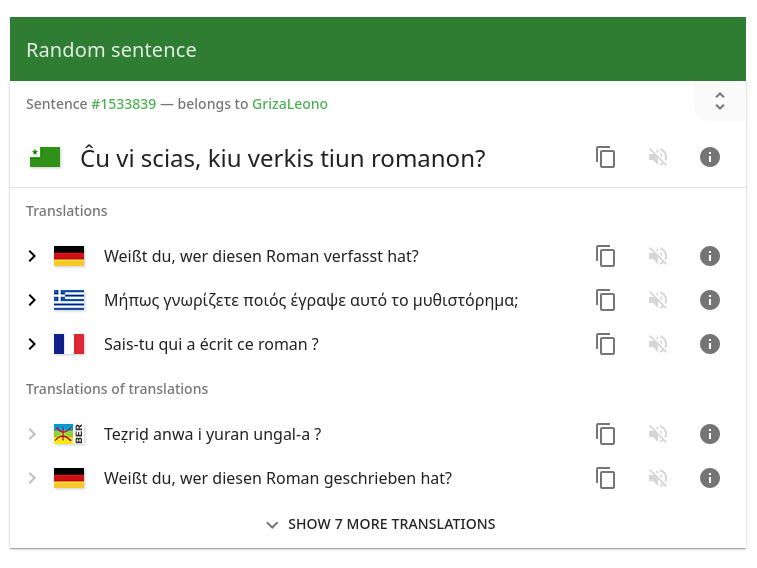
Tatoeba’dan bir cümle ve çevirileri
Kullanıcılar, herhangi bir dilde kelimeleri arayabilir, bu kelimelerin geçtiği cümleleri bulabilirler. Tatoeba veri tabanındaki her cümle, yanında diğer dillerdeki olası çevirileriyle birlikte gösterilir; doğrudan ve dolaylı çeviriler birbirinden ayrılır. Cümle içerikleri konu, diyalekt veya müstehcenlik gibi etkiletlerle belirtilir; ayrıca kültürel notlar ve diğer kullanıcılardan gelen geri bildirimler ve düzeltmeleri kolaylaştırmak için her birinin ayrı yorum zincirleri bulunur. Cümleler dil, etiket ve başka kriterlere göre aranabilir.
Kayıtlı kullanıcılar, hedef dil kendi ana dilleri olmasa bile yeni cümleler ekleyebilir veya mevcut cümleleri çevirebilir veya düzeltebilir. Ancak, kullanıcıların kendi ana dillerinde veya en iyi bildikleri dillerde orijinal cümleler veya çeviriler eklemeleri önerilir.
Tatoeba veritabanının tamamı Creative Commons Atıf 2.0 lisansı altında yayınlanmaktadır. Ayrıca, downloads sayfasından parça parça derlemleri tek dilli veya paralel biçimde indirmek çok kolaydır.
Konuşma derlemi
Bir konuşma derlemi (speech corpus/corpora), konuşma ses dosyalarının ve genellikle bunların metin transkripsiyonlarının bir toplamıdır. Konuşma teknolojisinde konuşma derlemleri otomatik konuşma tanıma, metin-konuşma sentezi veya konuşmacı tanımlama gibi görevler için akustik modeller oluşturmak için kullanılır.
Konuşma derlemi okunmuş (ör. sesli kitaplar, haberler, okunmuş sayı veya kelimeler) veya doğal konuşmalar (diyaloglar) içerebilir. ASR (otomatik konuşma tanıma) modelleri eğitmeye uygun derlemler, mümkün olduğunca çok konuşmacıdan çeşitli akustik ortamlarda (ör. gürültülü, uzaktan) toplanan örnek konuşmaları içerir. Bunun tersine, TTS eğitim verileri çoğu zaman ideal akustik ortamda tek bir konuşmacıdan alınan kayıtlardan oluşur.
OpenSLR halka açık birçok konuşma derlemini listeler.
Common Voice
Common Voice, konuşma tanımayı herkes için erişilebilir kılmak için ücretsiz bir veritabanı oluşturmak amacıyla Mozilla tarafından başlatılan bir kitle kaynaklı projedir. Proje, mikrofonla örnek cümleler kaydeden ve diğer kullanıcıların kayıtlarını kontrol eden gönüllüler tarafından desteklenir. Seslendirilmiş örnekler, CC0 kamu malı (public domain) lisansı altında düzenli aralıklarla yayınlanır. Bu lisans, geliştiricilerin veritabanını sesten-metne-çevirme uygulamaları için kısıtlama veya maliyet olmaksızın kullanabilmelerini sağlar.
Not
Mayıs 2022 itibarıyla Common Voice 63 dili desteklemektedir, 68 yeni dil de desteklenme aşamasındadır. Mevcut dil listesine buradan bakabilirsiniz.
Common Voice’ta Kurmanci Kürtçe bir cümle kaydetme
Common Voice’a dil ekleme
Common Voice, her dilin kendi topluluğuna sahip olduğu bir topluluk platformu olarak çalışır. Common Voice’a yeni bir dilin eklenmesi prosedürü aşağıdaki gibidir:
Dil için bir topluluk yöneticisi bulma (Roller hakkında bilgi)
Mozilla’ya yerelleştirme isteği gönderme Bu, github sayfalarında bu şablon kullanılarak yapılır. Bu işlem, istenen dili Pontoon’a yerleştirmek suretiyle Common Voice’un bu dile yerelleştirme sürecini başlatacaktır.
Pontoon’da yerelleştirme süreci (kullanım kılavuzu). Common Voice platformundaki her dize, stil kılavuzuna uygun olarak yerelleştirilmek istenen dile çevrilmelidir. Toplam 663 dize bulunur. Çeviriler, platforma kaydolan ve o dili konuşan herhangi bir kullanıcı tarafından yapılabilir, ancak bu çevirilerin topluluk yöneticisi tarafından gözden geçirilmesi gerekir.
Cümle toplama En az 5000 kamu malı olan cümlenin toplanması ve Common Voice cümle toplayıcıya girilmesi gerekir.
Cümlelerin gözden geçirilmesi Toplanan her cümle, cümle toplayıcıda en az iki kullanıcı tarafından manuel olarak kontrol edilmelidir.
Bir sonraki Common Voice sürümünü bekleme Yerelleştirme tamamlandığında ve 5000 cümlenin kontrolü bittiğinde, bir sonraki Common Voice sürümü dilinizi içerecektir. Sürümler ayda iki kez yapılır ve takvimleri github verihavuzunda listelenir.
Bulunmuş veriler
Ayrıca, radyo programlarından, filmlerden ve röportajlar gibi kayıtlı materyallerden ses verileri elde etmek de mümkündür. Bu tür veriler, orijinal olarak ses teknolojisi oluşturmaya hizmet etmesi amaçlanmadığı için “bulunmuş veriler” olarak adlandırılır, ancak başka bir amaca hizmet etmek üzere uyarlanır. Bulunmuşn verilerin kısa ses segmentleri ve bunların transkripsiyonlarını elde etmek için işlenmesi gerekir.
Kaynaklar

Bu yayın Avrupa Birliğinin maddi desteği ile hazırlanmıştır. İçerik tamamıyla Col·lectivaT ve SKAD’ın sorumluluğundadır ve Avrupa Birliğinin görüşlerini yansıtmak zorunda değildir.