
Este proyecto está financiado por la Unión Europea.
Estudios de caso
En esta sección, enumeramos algunas iniciativas y trabajos relacionados con la tecnología del lenguaje que consideramos ejemplares o inspiradores para las lenguas en peligro y minoritarias. Comenzaremos describiendo el proyecto que dio fruto a este documento «Judeo-Español: Conectando los dos extremos del Mediterráneo» y continuaremos con proyectos que involucran las lenguas anatólica, ibérica y africana.
Judeoespañol: Conectando las dos orrillas del Mediterráneo
Col·lectivaT y el Centro Sefardí de Estambul se han unido para llevar a cabo un conjunto diverso de actividades que van desde la creación de contenidos en redes sociales hasta el desarrollo de tecnología lingüística avanzada que ayuda al judeoespañol (ladino) hasta la era digital. También pretendía dar a conocer esta lengua como patrimonio común entre Turquía y España.
Creación de contenidos audiovisuales para redes sociales
El proyecto creó videos cortos de aprendizaje de idiomas que ayudarían a ganar visibilidad en las plataformas de redes sociales y atraerían a las generaciones jóvenes a aprender ladino. En estos videos cortos, se presenta una frase judeo-española con su traducción en turco, inglés y español con un audio que ayuda a aprender su pronuciación.

Promoción de Ladino en la página de Instagram de SKAD con vídeos de Fraza del diya (Una frase al día)
Ladino Data Hub y conjuntos de datos abiertos de lenguaje
El proyecto lanzó Ladino Data Hub que actuará como un archivo web centralizado dedicado a alojar datos en idioma ladino y otros recursos que ayudan a documentar la cultura sefardí. Su objetivo es permitir a investigadores y periodistas de todo el mundo acceder y compartir conjuntos de datos que ayudarían a impulsar la investigación y el desarrollo de Ladino.
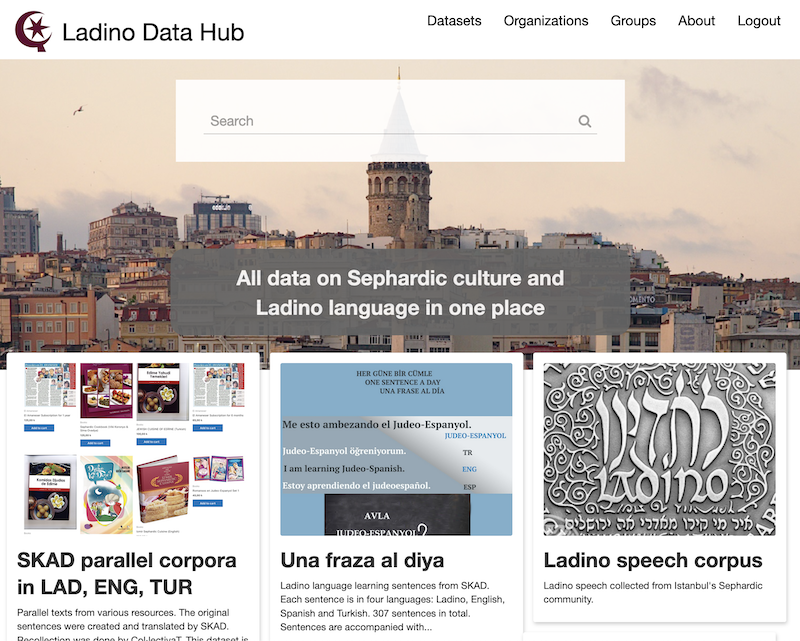
Ladino Data Hub alberga datos relacionados con la cultura ladina y sefardí
El proyecto creó y reenvasó conjuntos de datos ya existentes y compartidos en este portal. Estos son:
Un corpus de texto que consta de frases arrastradas desde el periódico Şalom.
Un corpus de texto paralelo con audio que contiene frases de Una Fraza al diya y su audio
Ladino speech corpus creado por SKAD
Conjunto de datos de entrenamiento de síntesis del habla limpia consiste en material de habla leída por Karen Şarhon
Un léxico ladino español basado en el diccionario de Güler, Portal i Tinoco
Textos paralelos en ladino, inglés y turco a partir de las traducciones realizadad en SKAD
Corpus paralelo producido sintéticamente para los modelos de MT de referencia de entrenamiento
Aplicación web para traducción automática y síntesis de voz
El resultado final y más importante del proyecto es una aplicación web que es capaz de traducir entre ladino y tres idiomas relacionados turco, español e inglés. El objetivo es ayudar a los estudiantes de idiomas, investigadores y lingüistas que quieran estudiar judeo-español. El back-end de traducción automática se construyó con la ayuda de un sistema de traducción automática basado en reglas que puede convertir del español al ladino, utilizando la sintaxis similar entre idiomas pero cambiando la ortografía y el vocabulario con un conjunto de reglas derivadas de diccionarios y libros de gramática. La aplicación web también puede sintetizar oraciones ladinas con una aplicación TTS que se creó con el conjunto de datos de capacitación TTS.
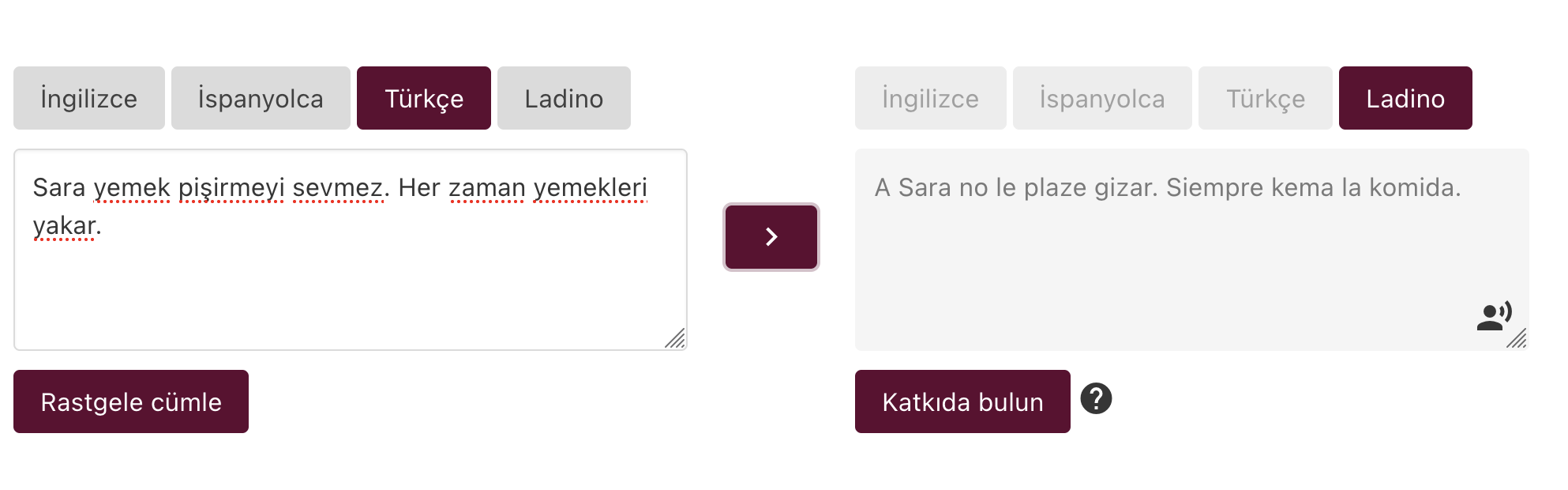
Aplicación web de traducción ladina con síntesis de voz
La aplicación web también permite la contribución de datos paralelos. Los usuarios pueden cargar una oración aleatoria y enviar su traducción corregida para extender los datos paralelos para Ladino.
Nota
Para obtener un informe técnico detallado de este proyecto, consulte el documento «Preparando una Lengua en Peligro para la Era Digital: El Caso del Judeo-Español» presentado en el Taller sobre Recursos y Tecnologías para las Lenguas Indígenas, en Peligro y de Menores Recursos en Eurasia (EURALI): Enlace que se colocará pronto
Comunidades de base PLN
Contra la investigación de la PLN centrada en un puñado de idiomas, las comunidades de investigación de base se organizan para llevar los idiomas del mundo a la vanguardia de la tecnología. Dos ejemplos de estas iniciativas son Masakhane y Turkic Interlingua.
Como se define en su página web, «Masakhane es una organización de base cuya misión es fortalecer y estimular la investigación de PLN en idiomas africanos, para los africanos, por los africanos.» Es una iniciativa abierta a todos para «construir juntos» como sugiere el significado de su nombre. Investigadores africanos y no africanos de todo el mundo llevan a cabo muchas actividades simultáneas con el objetivo de representar los 2000 idiomas de África en la investigación sobre tecnología lingüística. Algunos trabajos destacados de Masakhane son:
Traductor Masakhane apoyando 6 idiomas africanos: Yoruba, Shona, Lingala, Swahili, Tshiluba
Lanfrica catalogación de recursos lingüísticos africanos para contrarrestar las dificultades encontradas en el descubrimiento de obras lingüísticas africanas
BibleTTS desbloquear el desarrollo de modelos de texto a voz de alta calidad para diez idiomas hablados en el África subsahariana: ewe, hausa, kikuyu, lingala, luganda, luo, chichewa, akuapem twi, asante twi, yoruba.
Traducción automática para preservar el idioma y la cultura Oshiwambo
MasakhaNER Conozca nuestros nombres creando conjuntos de datos de reconocimiento de entidades con nombre (Ner) hechos a mano para varios idiomas africanos
Masakhane también organiza talleres anuales para publicar investigaciones relacionadas con la PLN africana y participa en fondos de recopilación de datos como Lacuna.
Turkic Interlingua (TIL) es una «comunidad de investigadores, ingenieros, entusiastas del lenguaje y líderes comunitarios cuya misión es desarrollar tecnologías lingüísticas (desde correctores ortográficos hasta modelos de traducción), recopilar diversos conjuntos de datos y explorar fenómenos lingüísticos a través de la lente de la investigación académica para las lenguas túrquicas» como Altai, Azerbaijani, Bashkir, Shor, Crimean Tatar, Chuvash, Gagauz, Karakalpak, Khakas, Kazakhstan, Karachay-Balkar, Kumyk, Kirghiz, Sakha (Yakut), Salar, Turkmen, Turkish, Tatar, Tuvinian, Uighur, Urum y Uzbek.
Campañas de Common Voice
Varias comunidades lingüísticas se han embarcado en la movilización de la participación en Common Voice. Estas iniciativas son preparadas por grupos que van desde individuos individuales hasta gobiernos locales. Algunos ejemplos son:
Comunidad Igwebuike para Igbo
Proyecto AINA para catalán
También nos gustaría hacer una mención especial a la comunidad catalana por su contribución a Common Voice. Siendo una lengua minoritaria apátrida en España, es la cuarta lengua más grande (a partir de mayo de 2022) en Common Voice gracias a las increíbles contribuciones de los activistas y también a una campaña de movilización por parte de la iniciativa de IA del gobierno local catalán.

Cartelera con «Es hora de que Internet hable catalán» que se exhibe en Times Square de Nueva York (foto de Aina Martí)
Otras iniciativas
Otras iniciativas:
Col·lectivaT ha creado open speech data and text corpora for Catalan utilizando emisiones de televisión pública y procedimientos parlimantarios.
Catotron es el primer motor de síntesis de voz de código abierto basado en una red neuronal para catalán construido con el apoyo del Departamento de Cultura de Cataluña.
Cebuano y Waray-Waray, idiomas de Filipinas, tiene una de las páginas de Wikipedia más grandes gracias al uso competitivo de la traducción automática (source)
El pueblo maorí ha rechazado las iniciativas privadas y de código abierto para recopilar datos de voz en su idioma a fin de «mantener el derecho a la libre determinación» (fuente)
ELLORA habilitando idiomas de bajos recursos por Microsoft Research India

Este documento fue creado con el apoyo financiero de la Unión Europea. El contenido de este sitio web es responsabilidad exclusiva de Col·lectivaT y SKAD, y no refleja necesariamente las opiniones de la Unión Europea.