
Este proyecto está financiado por la Unión Europea.
Datos lingüísticos
Las herramientas de inteligencia artificial abren una nueva área para la creación de recursos lingüísticos para las lenguas minoritarias y en peligro de extinción. En comparación con los recursos lingüísticos «clásicos» creados para preservar idiomas como la léxica, la documentación gramatical, los mapas lingüísticos, etc., estos requieren menos conocimientos lingüísticos, pero por lo general solo son útiles en grandes volúmenes.
En esta sección explicaremos los tipos de datos que impulsan la creación de tecnología del lenguaje basada en inteligencia artificial explicada en el capítulo anterior. Además, cubriremos algunas formas de recopilarlos y obtener el máximo provecho de ellos, incluso si no son de grandes volúmenes que suelen requerir estas aplicaciones.
Corpus de texto
En lingüística, un corpus (corpus plural) o corpus de texto es un recurso lingüístico que consiste en un conjunto grande y estructurado de textos en un idioma en formato digital. Son útiles en lingüística de corpus para hacer análisis estadísticos y pruebas de hipótesis, verificar ocurrencias o validar reglas lingüísticas dentro de un territorio lingüístico específico. Para la tecnología del lenguaje, son una parte esencial en la creación de modelos de lenguaje estadísticos que se utilizan en aplicaciones como el reconocimiento óptico de caracteres, el reconocimiento de escritura a mano, la traducción automática, la corrección ortográfica y la escritura asistida.
Los corpus de texto por sí mismos son del tipo * datos sin etiquetar *. Es decir, son una mera recopilación de datos (en este caso texto) sin anotaciones ni etiquetado. Los modelos de lenguaje almacenan las probabilidades de secuencias de palabras para obtener una «comprensión» del lenguaje. Además, los corpus de texto se pueden anotar con la siguiente información para crear * datos etiquetados * para diferentes tareas de PLN:
Parte del discurso (sustantivo, verbo, adjetivo, etc.)
Entidades nombradas (Persona, ubicación, información de identificación personal, organización, hora, etc.)
Lemas (raíces de las palabras, por ejemplo, venir por venga)
Estructura de dependencia y frase (árbol sintáctico)
Obtención de corpus de texto
La forma más común de obtener corpus de texto es a través de rastreo de la World Wide Web. Esta técnica analiza toda la web para recopilar texto en un idioma determinado o en muchos idiomas a la vez. Wikipedia publica su contenido en diferentes idiomas que se pueden utilizar para crear corpus de texto. Common Crawl initiative recopila datos del sitio web y proporciona libremente petabytes de datos. OSCAR distribuye estos datos clasificados en 166 idiomas.
Otro recurso común utilizado por los idiomas ingeniosos son los libros. BookCorpus consta de 11.038 libros de la web que contienen 74 millones de frases y 984 millones de palabras y se sabe que ha impulsado muchos modelos de lenguaje influyentes por las grandes empresas tecnológicas.
Nota
Los modelos de lenguaje que se crean a partir de datos en la naturaleza representan lo que ven, y nada más. El lenguaje en la web y los libros también contienen sesgos, lenguaje tóxico que eventualmente se replica en estos modelos. Para un análisis de los riesgos potenciales de construir modelos de lenguaje a partir de grandes corpus de lenguaje, consulte este artículo de Bender et al.
Datos paralelos (bitext)
El tipo de datos que se necesitan para construir un sistema de traducción automática son datos paralelos, que consisten en una colección de oraciones en un idioma junto con sus traducciones. Históricamente, los datos paralelos se obtuvieron de traducciones en espacios públicos multilingües como las Naciones Unidas y el Parlamento Europeo. Ahora, el mayor recurso de texto paralelo es la web multilingüe.
Con el fin de entrenar a los modelos de traducción automática no es suficiente sólo tener documentos traducidos. Los textos deben segmentarse en oraciones y alinearse. La alineación de texto paralelo es la identificación de las oraciones correspondientes a ambos lados del texto paralelo. Los documentos resultantes deben corresponder línea por línea o contener las oraciones originales y sus traducciones en la misma línea. Hunalign ayuda a crear alineaciones de oraciones a partir de documentos traducidos. Las memorias de traducción (archivos TMX) también hacen grandes datos paralelos, ya que ya están segmentados por oraciones.
Obtención de datos paralelos
OPUS es una recopilación de casi todos los datos paralelos disponibles públicamente. Es el punto de referencia para que muchos investigadores publiquen sus datos paralelos o datos de origen para el desarrollo de modelos de TA.
Algunas fuentes comunes de datos paralelos son: - sitios web multilingües (por ejemplo, medios de comunicación internacionales), - subtítulos de películas (véase OpenSubtitles), - textos sagrados, - procedimientos parlamentarios, - datos de localización de software.
Crowdsourcing de datos paralelos con Tatoeba.org
Tatoeba es una colección gratuita de oraciones de ejemplo con traducciones dirigidas a estudiantes de idiomas extranjeros. Está escrito y mantenido por una comunidad de voluntarios a través de un modelo de colaboración abierta. Está organizado por la Asociación Tatoeba, una organización francesa sin fines de lucro financiada mediante donaciones. Actualmente tiene 10.397.308 sentencias en 412 idiomas admitidos.
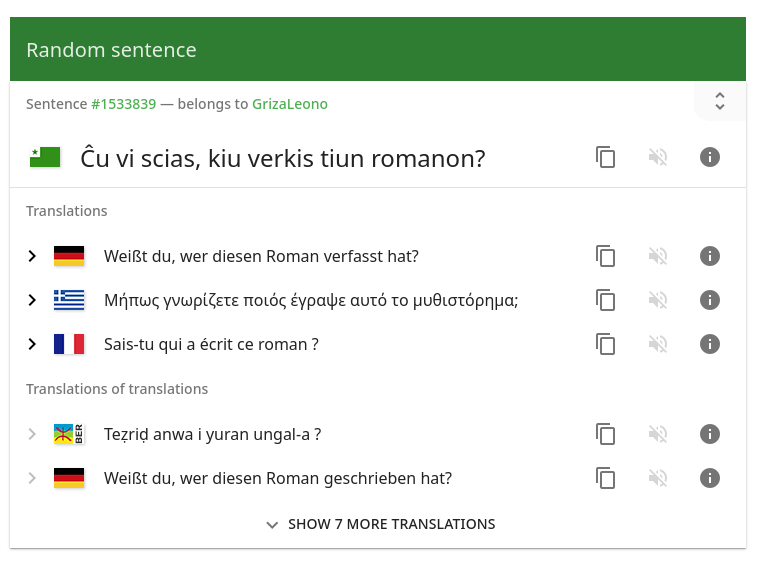
Una frase y sus traducciones de Tatoeba
Los usuarios pueden buscar palabras en cualquier idioma para recuperar oraciones que las usen. Cada oración en la base de datos de Tatoeba se muestra junto a sus traducciones probables en otros idiomas; las traducciones directas e indirectas se diferencian. Las oraciones se etiquetan por contenido como tema, dialecto o vulgaridad; también tienen hilos de comentarios individuales para facilitar la retroalimentación y las correcciones de otros usuarios y notas culturales. Las oraciones se pueden examinar por idioma, etiqueta y otros criterios.
Los usuarios registrados pueden añadir nuevas frases o traducir o corregir las existentes, incluso si su idioma de destino no es su lengua materna. Sin embargo, se anima a los usuarios a añadir oraciones originales o traducciones en su idioma nativo o más fuerte.
Toda la base de datos Tatoeba se publica bajo una licencia Creative Commons Atribución 2.0. También es muy fácil descargar partes de corpus en formato monolingüe o paralelo desde su página de descargas.
Corpus del habla
Un corpus de voz es una colección de archivos de audio de voz que generalmente se acompañan con sus transcripciones de texto. En la tecnología del habla, los corpus del habla se utilizan para crear modelos acústicos para tareas como el reconocimiento automático de voz, la síntesis de texto a voz y también la identificación de altavoces.
Los corpus de habla pueden contener lectura (por ejemplo, audiolibros, noticias, números y palabras leídas) o habla espontánea (diálogos). El adequeato de corpus para los modelos ASR de entrenamiento contiene muestras de tantos altavoces como sea posible y en diversos entornos acústicos (por ejemplo, ruidoso, de lejos). Por el contrario, los datos de entrenamiento para TTS generalmente contienen grabaciones de un altavoz en un entorno acústicamente óptimo.
OpenSLR lista muchos corpus de discursos disponibles públicamente.
Common Voice
Common Voice es un proyecto de crowdsourcing iniciado por Mozilla para crear una base de datos gratuita para hacer que el reconocimiento de voz sea accesible para todos. El proyecto cuenta con el apoyo de voluntarios que registran oraciones de muestra con un micrófono y revisan las grabaciones de otros usuarios. Las muestras con voz se publican a intervalos regulares bajo la licencia de dominio público CC0 (dominio público). Esta licencia garantiza que los desarrolladores puedan utilizar la base de datos para aplicaciones de voz a texto sin restricciones ni costes.
Nota
A partir de mayo de 2022, Common Voice admite 63 idiomas con 68 nuevos en camino. Consulta aquí la lista actual de idiomas: https://commonvoice.mozilla.org/en/languages.
Grabación de una sentencia kurda Kurmanji en Common Voice
Añadir un idioma a Common Voice
Common Voice funciona como una plataforma comunitaria donde cada idioma tiene su propia comunidad. El procedimiento para añadir un nuevo lenguaje en Common Voice es el siguiente:
Encuentre un administrador de la comunidad para el idioma (Información sobre roles)
Solicitud de localización a Mozilla Esto se hace utilizando esta plantilla en su página de github. Esto iniciará el proceso de localización de Common Voice al idioma deseado colocándolo en Pontoon.
Localización en Pontoon (manual de usuario) Cada cadena en la plataforma Common Voice necesita ser traducida al idioma respetando la guía de estilo. En total hay 663 cuerdas. Las traducciones pueden ser realizadas por cualquier orador que se registre en la plataforma, pero deben ser revisadas por el administrador de la comunidad.
Recopilación de oraciones Se debe recopilar un mínimo de 5000 oraciones de dominio público e ingresar a Common Voice sentence Collector.
Revisar frases Cada frase recopilada debe ser revisada manualmente por al menos dos usuarios en el recopilador de oraciones.
Espere a la próxima versión del CV Una vez que se complete la localización y haya 5000 oraciones revisadas, la próxima versión del CV debe contener su idioma. Los lanzamientos se realizan dos veces al mes con los horarios listados en su repositorio de github.
Datos encontrados
También es posible obtener datos de voz de programas de radiodifusión, películas y otros materiales grabados, como entrevistas. Este tipo de datos se denomina «datos encontrados», ya que originalmente no está destinado a servir para construir tecnología de voz, sino que se reutiliza para hacerlo. Los datos encontrados requieren ser procesados para obtener segmentos de audio cortos y sus transcripciones.
Fuentes

Este documento fue creado con el apoyo financiero de la Unión Europea. El contenido de este sitio web es responsabilidad exclusiva de Col·lectivaT y SKAD, y no refleja necesariamente las opiniones de la Unión Europea.