
This project is funded by the European Union.
Case studies
In this section, we list some language technology-related initiatives and works that we deem exemplary or inspiring for endangered and minority languages. We will start with describing the project which gave fruit to this document “Judeo-Spanish: Connecting the two ends of the Mediterranean” and continue with projects that involve Anatolian, Iberian and African languages.
Judeo-Spanish: Connecting the two ends of the Mediterranean
Col·lectivaT and Sephardic Centre of Istanbul have come together for this project to carry out a diverse set of activities ranging from social media content creation to development of advanced language technology that assist Judeo-Spanish (Ladino) to the digital age. It also aimed to form awareness on this language as a common heritage between Turkey and Spain.
Creation of audio-visual content for social media
The project created short language learning videos that would help gain visibility in social-media platforms and attract young generations to learn Ladino. In these short videos, a Judeo-Spanish phrase is presented with its translation in Turkish, English and Spanish with an audio helping to learn its pronuciation.

Promoting Ladino on SKAD’s instagram page with Fraza del diya (One sentence a day) videos
Ladino Data Hub and open language datasets
The project launched Ladino Data Hub which will act as a centralized web archive dedicated to host Ladino language data and other resources that help document Sephardic culture. It aims to enable researchers, journalists from all over the world to access and share datasets that would help boost research and development for Ladino.
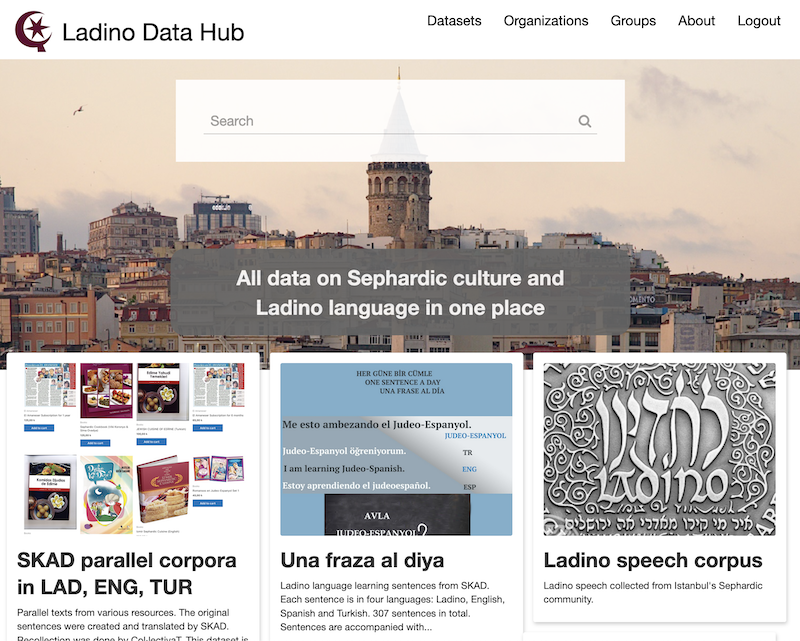
Ladino Data Hub hosts data related to Ladino and Sephardic culture
The project created and repackaged already existing datasets and shared in this portal. These are:
A text corpus consisting of sentences crawled from Şalom newspaper.
A parallel text corpus with audio that contains Una Fraza al diya sentences and their audio
Ladino speech corpus created by SKAD
Clean speech sythesis training dataset consisting of read speech material by Karen Şarhon
A Spanish Ladino lexicon based on dictionary by Güler, Portal i Tinoco
Parallel texts in Ladino English and Turkish from translations made within SKAD
Synthetically produced parallel corpus for training baseline MT models
Web application for machine translation and speech synthesis
The final and most important output of the project is a web application that is able to translate between Ladino and three related languages Turkish, Spanish and English. The objective is to help language learners, researchers and linguists who want to study Judeo-Spanish. The machine translation back-end was built with the help of a rule based machine translation system that can convert from Spanish to Ladino, getting use of the similar syntax between languages but changing ortography and vocabulary with a set of rules derived from dictionaries and grammar books. The web app is also able to synthesize Ladino sentences with a TTS application which was built with the TTS training dataset.
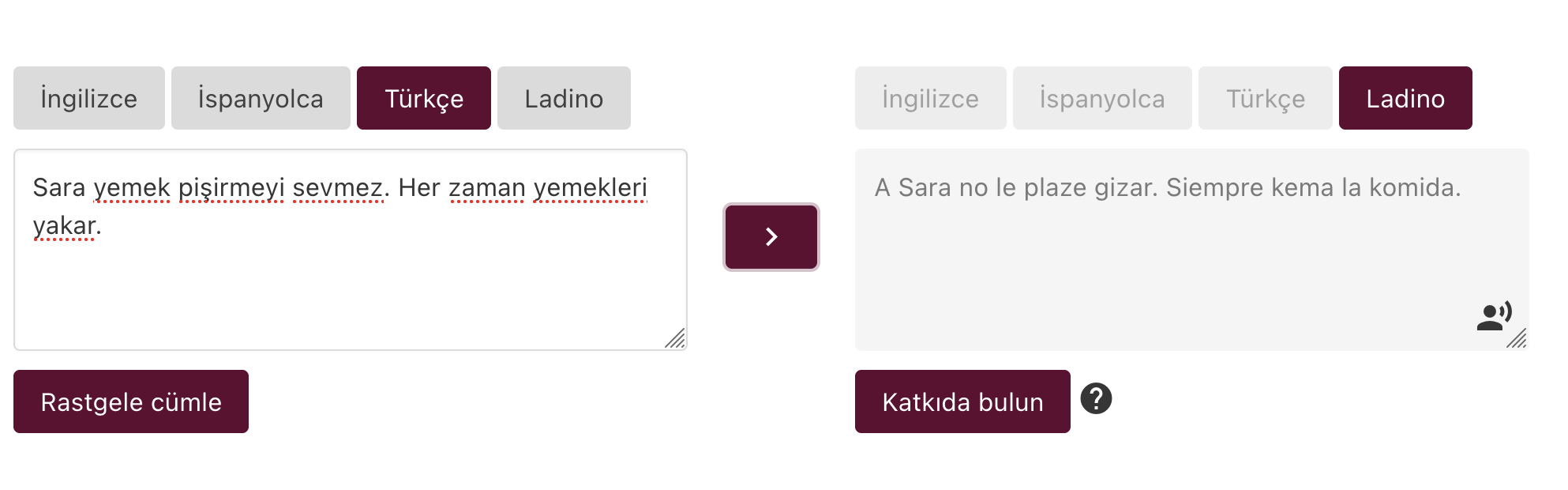
Ladino translation web app with speech synthesis
The web application also allows contribution of parallel data. Users can load a random sentence and submit their corrected translation in order to extend the parallel data for Ladino.
Note
For a detailed technical report of this project, please refer the paper “Preparing an Endangered Language for the Digital Age: The Case of Judeo-Spanish” presented in the Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia (EURALI): Link to be placed soon
Grassroots NLP communities
Against the NLP research focusing on a handful of languages, grassroots research communities organize together to bring the world’s languages into the forefront of technology. Two examples of these initiatives are Masakhane and Turkic Interlingua.
As defined in their web-page, “Masakhane is a grassroots organisation whose mission is to strengthen and spur NLP research in African languages, for Africans, by Africans.” It’s an open-for-all initiative for “building together” as the meaning of their name suggests. Many concurrent activities take place by African and non-African researchers all over the world with the objective of representing the 2000 languages of Africa in language technology research. Some highlighting work from Masakhane are:
Masakhane translator supporting 6 African languages: Yoruba, Shona, Lingala, Swahili, Tshiluba
Lanfrica cataloguing African language resources to counter difficulties encountered in discovering African language works
BibleTTS unlocking the development of high-quality Text-to-Speech models for ten languages spoken in Sub-Saharan Africa: Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, Chichewa, Akuapem Twi, Asante Twi, Yoruba.
Machine translation for preserving Oshiwambo language and culture
MasakhaNER Know our names creating hand-crafted named entity recognition (NER) datasets for various African languages
Masakhane also organizes annual workshops for publishing research related to African NLP and participates in data collection funds like Lacuna.
Turkic Interlingua (TIL) is a “community of researchers, engineers, language enthusiasts and community leaders whose mission is to develop language technologies (from spell checkers to translation models), collect diverse datasets, and explore linguistic phenomena through the lens of academic research for Turkic languages” like Altai, Azerbaijani, Bashkir, Shor, Crimean Tatar, Chuvash, Gagauz, Karakalpak, Khakas, Kazakh, Karachay-Balkar, Kumyk, Kirghiz, Sakha (Yakut), Salar, Turkmen, Turkish, Tatar, Tuvinian, Uighur, Urum, and Uzbek.
Common Voice campaigns
Various language communities have embarked on mobilizing participation into Common Voice. These initiatives are prepared by groups ranging from single individuals to local governments. Some examples are:
Igwebuike community for Igbo
Projecte AINA for Catalan
We also would like to give a special mention to the Catalan community for their contribution to Common Voice. Being a stateless minority language in Spain, it’s the 4th largest language (as of May 2022) in Common Voice thanks to the amazing contributions by activists and also a mobilization campaign by the AI initiative of Catalan local government.

Billboard with “It’s time the Internet speaks Catalan” being displayed on New York’s Times Square (photo by Aina Martí)
Other initiatives
Some other initiatives worth mentioning:
Col·lectivaT has created open speech data and text corpora for Catalan using public television broadcasts and parlimantary proceedings.
Catotron is the first open-source, neural network-based speech synthesis engine for Catalan built with support from Department of Culture of Catalonia.
Cebuano and Waray-Waray, languages of Phillipines, has one of the biggest Wikipedia pages thanks to competitive usage of machine translation (source)
Maori people have rejected both private and open-source initiatives for collecting voice data in their language in order to “maintain the right to self-determination” (source)
ELLORA Enabling Low Resource Languages by Microsoft Research India

This document was created with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and SKAD and does not necessarily reflect the views of the European Union.