
This project is funded by the European Union.
Language data
Artificial intelligence tools opens up a new area for language resource creation for endangered and minority languages. Compared to the “classic” language resources created to preserve languages like lexica, grammar documentation, language maps etc., these require less linguistic expertise but are usually only useful in large volumes.
In this section we will explain the types of data that power the creation of artificial intelligence-based language technology explained in the previous chapter. Also, we will cover some ways to collect them and get the most out of them even if they are not of large volumes usually required by these applications.
Text corpus
In linguistics, a corpus (plural corpora) or text corpus is a language resource consisting of a large and structured set of texts in a language in digital format. They are useful in corpus linguistics for doing statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory. For language technology, they are an essential part in creating statistical language models that are used in applications such as optical character recognition, handwriting recognition, machine translation, spelling correction and assisted writing.
Text corpora by themselves are of the type unlabeled data. That is, they are a mere collection of data (in this case text) without any annotations or labelling. Language models store the probabilities of sequences words in order to get an “understanding” for the language. Also, text corpora can be annotated with following information in order to create labeled data for different NLP tasks:
Part-of-speech (Noun, verb, Adjective etc.)
Named entities (Person, location, personally identifiable information, organization, time etc.)
Lemmas (roots of the words e.g. break for broken)
Dependency and phrase structure (syntactic tree)
Sourcing text corpora
The most common way of sourcing text corpora is through crawling the world wide web. This technique parses the whole web for collecting text in a certain language or many languages at once. Wikipedia publishes its content in different languages which can be used to create text corpora. Common Crawl initiative collects web site data and freely provides petabytes of data. OSCAR distributes this data classified into 166 languages.
Another common resource used by resourceful languages are books. BookCorpus consists of 11,038 books from the web containing 74 Million sentences and 984 Million words and is known to have powered many influential language models by big tech companies.
Note
Language models that are created from data in the wild represent what they see, and nothing else. Language in the web and books contain as well biases, toxic language which eventually gets replicated in these models. For an analysis of potential risks of building language models out of big language corpora, refer to this paper by Bender et al.
Parallel data (bitext)
The type of data that is needed to build a machine translation system is parallel data, which consists of a collection of sentences in a language together with their translations. Historically, parallel data were sourced from translations in multilingual public spaces like United Nations, European Parliament. Now, the greatest resource of parallel text is the multilingual web.
In order to train machine translation models it is not enough just to have translated documents. The texts need to be segmented to sentences and aligned. Parallel text alignment is the identification of the corresponding sentences in both sides of the parallel text. The resulting documents either have to correspond line by line or contain the original sentences and their translations in the same line. Hunalign helps in creating sentence alignments from translated documents. Translation memories (TMX files) also make great parallel data as they are already sentence segmented.
Sourcing parallel data
OPUS is a collection of almost all publicly available parallel data. It is the go-to point for many researchers to publish their parallel data or source data for development of MT models.
Some common sources for parallel data are: - Multilingual web sites (e.g. international news outlets), - Movie subtitles (see OpenSubtitles), - Holy texts, - Parliament proceedings, - Software localization data.
Crowdsourcing parallel data with Tatoeba.org
Tatoeba is a free collection of example sentences with translations geared towards foreign language learners. It is written and maintained by a community of volunteers through a model of open collaboration. It is hosted by Tatoeba Association, a French non-profit organization funded through donations. It currently holds 10,397,308 sentences in 412 supported languages.
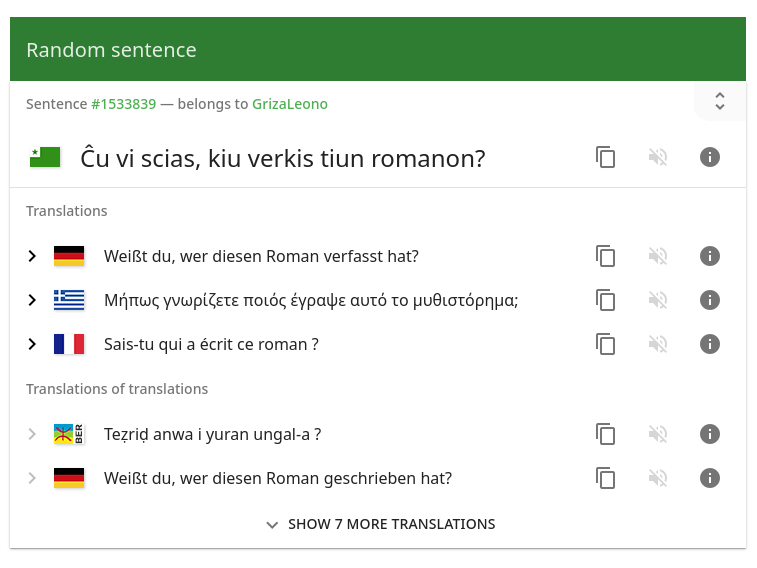
A sentence and its translations from Tatoeba
Users can search for words in any language to retrieve sentences that use them. Each sentence in the Tatoeba database is displayed next to its likely translations in other languages; direct and indirect translations are differentiated. Sentences are tagged for content such as subject matter, dialect, or vulgarity; they also each have individual comment threads to facilitate feedback and corrections from other users and cultural notes. Sentences can be browsed by language, tag, and other criteria.
Registered users can add new sentences or translate or proofread existing ones, even if their target language is not their native tongue. However, users are encouraged to add original sentences or translations in their native or strongest language.
The entire Tatoeba database is published under a Creative Commons Attribution 2.0 license. It is also very easy to download parts of corpora in monolingual or parallel format from its downloads page.
Speech corpus
A speech corpus is a collection of speech audio files usually accompanied with their text transcriptions. In speech technology, speech corpora are used to create acoustic models for tasks like automatic speech recognition, text-to-speech synthesis and also speaker identification.
Speech corpora can contain read (e.g. audiobooks, news, read numbers and words) or spontaneous speech (dialogues). Corpora adequeate for training ASR models contain samples from as many speakers as possible and in various acoustic settings (e.g. noisy, from far). In contrast, training data for TTS contains usually recordings from one speaker in an acoustically optimal setting.
OpenSLR lists many publicly available speech corpora.
Common Voice
Common Voice is a crowdsourcing project started by Mozilla to create a free database for making speech recognition accessible to everyone. The project is supported by volunteers who record sample sentences with a microphone and review recordings of other users. The voiced samples are released in regular intervals under the public domain license CC0 (public domain). This license ensures that developers can use the database for voice-to-text applications without restrictions or costs.
Note
As of May 2022, Common Voice supports 63 languages with 68 new on the way. Check here the current list of languages: https://commonvoice.mozilla.org/en/languages.
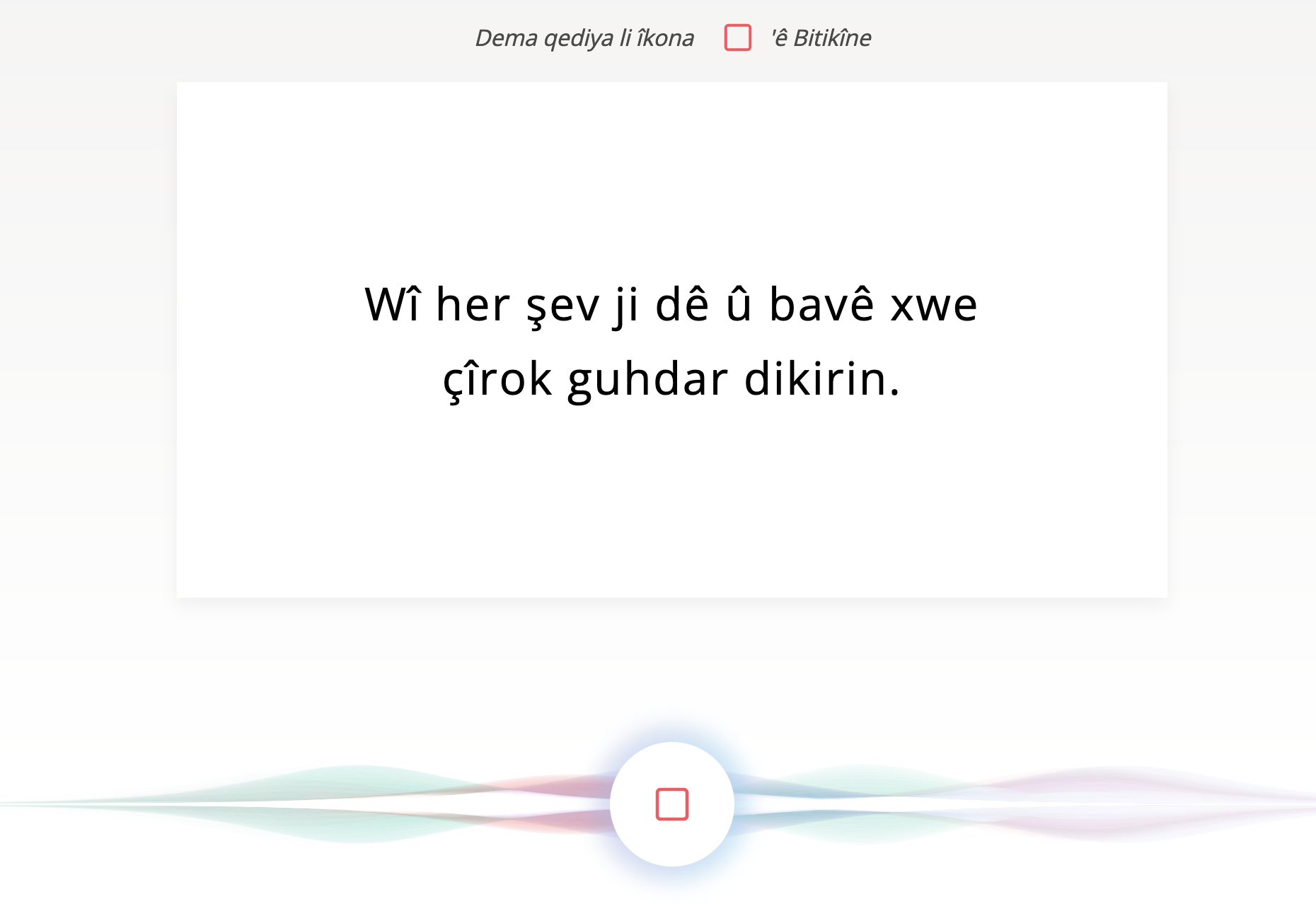
Recording a Kurmanji Kurdish sentence on Common Voice
Adding a language to Common Voice
Common Voice works as a community platform where each language has their own community. The procedure for adding a new language into Common Voice is as follows:
Find a community manager for the language (Information on roles)
Localization request to Mozilla This is done using this template on their github page. This will start the localization process of Common Voice to the desired language by placing it on Pontoon.
Localization on Pontoon (user manual) Every string on Common Voice platform needs to be translated to the language respecting the style guide. In total there are 663 strings. Translations can be made by any speaker who registers to the platform, but they need to be reviewed by the community manager.
Sentence collection A minimum of 5000 public domain sentences needs to be collected and entered to Common Voice sentence collector.
Reviewing sentences Each collected sentence needs to be reviewed manually by at least two users on sentence collector.
Wait for next CV release Once localization is complete and there are 5000 reviewed sentences, next CV release should contain your language. Releases are done done twice a month with schedules listed on their github repository.
Found data
It is also possible to source voice data from broadcast radio shows, movies and other recorded material like interviews. This type of data is called “found data” as it is not originally intended to serve for builing voice technology but it is repurposed to do so. Found data requires to be processed in order to obtain short audio segments and their transcriptions.
Sources

This document was created with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and SKAD and does not necessarily reflect the views of the European Union.